 ECONOVATION
ECONOVATION
안녕하세요, 에코노베이션 29기 안성준입니다 😊 저는 현재 NoBrains팀에서 제주 게스트하우스 플랫폼 게하르방의 백엔드 개발을 담당하고 있습니다. 저희 프로젝트에서 트랜스포머 인코더-디코더 모델을 활용한 텍스트 요약 AI를 개발하게 되면서, 이번 기회에 트랜스포머 모델을 제대로 이해하고 공유해보자는 목표로 트랜스포머 3부작 시리즈를 기획하게 되었습니다. 그럼 바로 시작해보도록 하겠습니다.
트랜스포머는 문장이나 소리 등 순서가 있는 데이터에서 중요한 부분을 자동으로 찾아내 처리하는 딥러닝 모델입니다. 트랜스포머는 기존에 순서가 있는 데이터의 시간적 의존성을 다루기 위해 사용했던 순환 신경망(RNN)의 순차적인 처리 방식과는 달리, 모든 데이터를 동시에 병렬로 처리해 RNN보다 훨씬 빠르고 효율적으로 학습할 수 있습니다. 이러한 트랜스포머 모델은 데이터를 이해하는 단계인 인코더(encoder)와 데이터를 이해한 바탕으로 결과를 생성하는 디코더(decoder) 구조로 이루어져 있는데, 이번 시간에 본격적으로 알아보도록 합시다.
1. 어텐션 메커니즘
트랜스포머의 핵심은 어텐션이라는 개념에 있습니다. 어텐션 메커니즘(attention mechanism)은 모델에 입력된 데이터의 모든 단어 중 특정 단어와 관련이 높은 단어에 집중해 데이터를 처리하도록 설계된 기법으로 여러 종류가 있습니다.
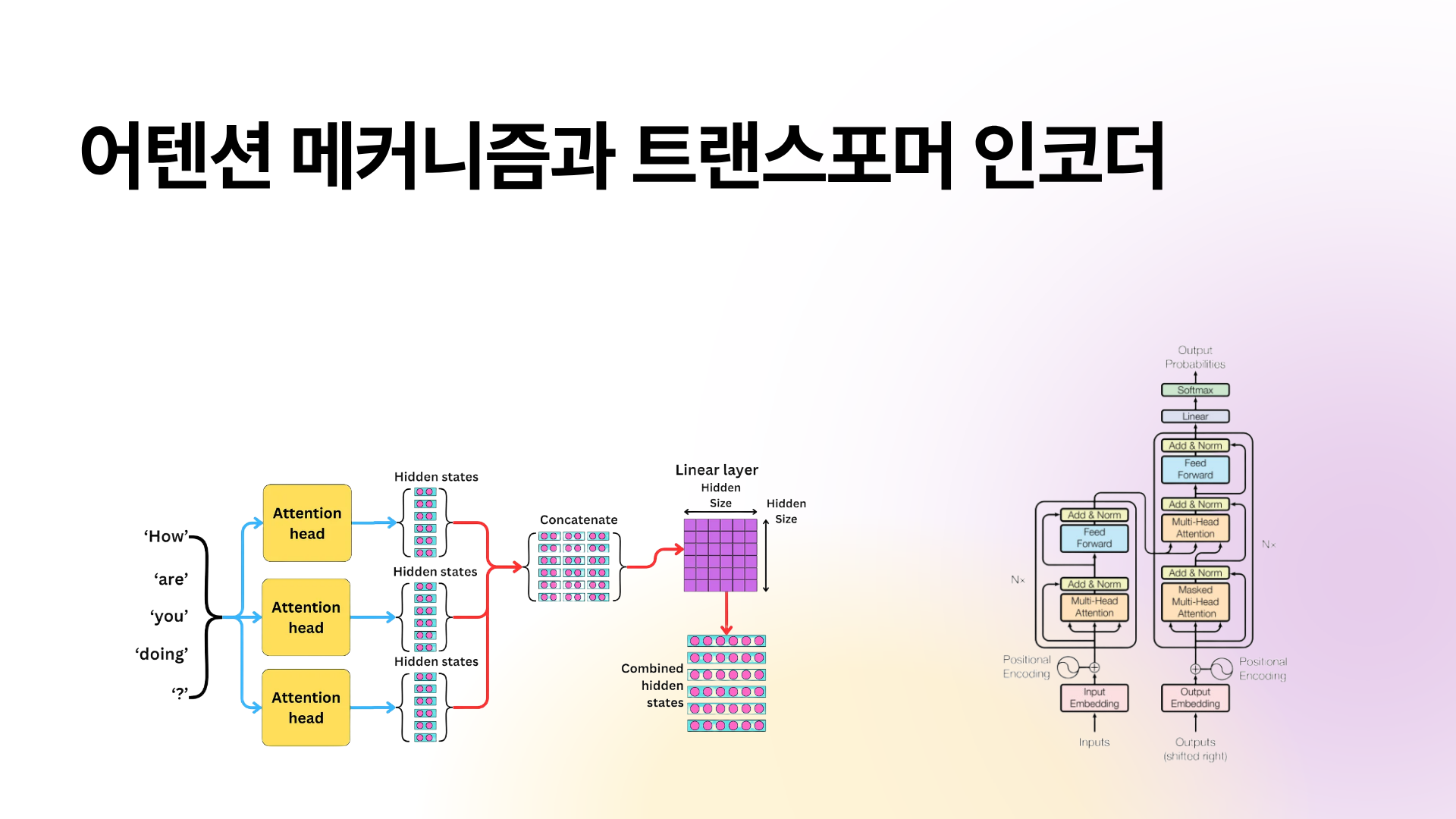
셀프 어텐션 : 어텐션 메커니즘의 한 종류로 문장의 모든 단어가 서로를 참고해 각각 다른 단어와의 관련성을 파악(계산)하는 방법
멀티 헤드 어텐션 : 여러 개의 셀프 어텐션을 동시에 수행해 이 관련성을 다양한 관점에서 더 깊게 이해할 수 있도록 확장한 방법
이러한 어텐션 개념은 영어로 입력된 문장을 한국어로 번역하는 것처럼 한 언어를 다른 언어의 문장으로 변환할 때 매우 유용하게 사용됩니다. 이러한 기계 번역에서 인코더 RNN은 먼저 입력된 문장을 처리하여 최종 은닉 상태로 만드는데, 이를 종종 문맥 벡터(context vector)라고 부릅니다.
문맥 벡터는 문장의 중요 정보가 담긴 일종의 요약본이라고 할 수 있는데, 그 다음 디코더 RNN이 인코더로부터 받은 문맥 벡터를 사용하여 새로운 문장(번역된 문장)을 생성하게 됩니다.
하지만 긴 문장일수록 정확한 번역이 어려울 수 있습니다. RNN은 긴 시퀀스의 텍스트를 잘 처리하도록 발전해왔지만 여전히 많은 한계를 가지고 있는데, 특히 입력되는 텍스트가 길수록 중요한 단어와 덜 중요한 단어가 섞여 있어 문맥 벡터만으로는 오래된 단어의 정보를 기억하기가 힘듭니다. 이는 그레이디언트가 여러 타임스텝(timestep)에 걸쳐 전파되면서 점점 약해지기 때문입니다.
타임스텝은 RNN이 하나하나의 단어를 시간의 순서에 따라 처리하는 과정을 의미합니다. RNN은 문장의 각 단어를 하나씩 순서대로 처리하는데, 이때 각 단어를 처리하는 한 단계를 타임스텝이라고 부릅니다.
어텐션 메커니즘은 인코더의 마지막 타임스텝에서 얻은 은닉 상태뿐만 아니라, 인코더의 모든 은닉 상태를 디코더가 텍스트를 생성할 때마다 참고하도록 만듭니다. 문장에서 특히 중요한 단어들에 더 집중하도록 도와줌으로써 번역의 정확도를 높입니다. 중요한 점은 디코더가 ‘모든’ 타임스텝에서 인코더의 은닉 상태를 참고해 문맥 벡터를 만든다는 점으로, 이러한 어텐션 메커니즘은 수식을 통해 알아보면 쉽습니다.
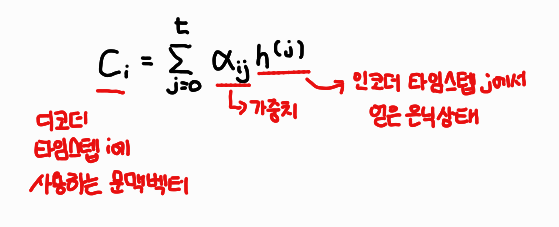
디코더의 타임스텝 i에서 사용하는 문맥 벡터는 인코더가 각 타임스텝에서 생성하는 모든 은닉 상태의 가중치 합으로, 디코더는 인코더의 은닉 상태에 곱해지는 가중치를 통해 어떤 단어에 주의를 기울일지 결정할 수 있습니다.
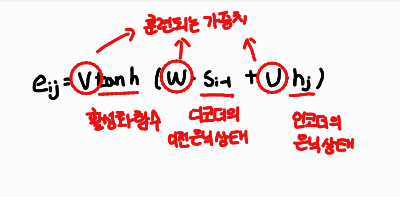
인코더의 은닉 상태에 곱해지는 가중치도 아래와 같은 수식을 통해 훈련되고, 최종적으로 계산된 eij의 결과를 소프트맥스 함수에 통과시켜 가중치의 값을 얻습니다. 소프트맥스 함수를 사용했기 때문에 인코더의 각 은닉 상태에 대한 가중치를 모두 더하면 1이 됩니다.
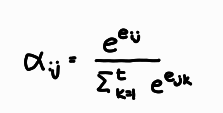
이렇게 인코더의 은닉 상태와 디코더의 은닉 상태를 더하는 어텐션은 논문 발표자의 이름을 따서 바흐다나우 어텐션(Bahdanau attention)이라고 부르기도 하고, 인코더의 출력과 디코더의 은닉 상태를 더하기 때문에 덧셈 어텐션 또는 연결 어텐션이라고도 부릅니다. 더 나아가 2015년에는 인코더의 최종 은닉 상태와 디코더의 은닉 상태를 더하는 것이 아닌 곱하는 방식으로 계산하는 새로운 어텐션이 개발되었는데, 이 어텐션은 루옹 어텐션(Luong attention) 또는 점곱 어텐션이라고 부릅니다.

케라스에서는 이 두 가지 방식의 어텐션 모두 layers.Attention 클래스로 제공하는데, Attention 클래스의 score_mode 매개변수의 기본값인 'dot'는 점곱 어텐션을 수행하고, score_mode 매개변수를 'concat', use_scale 매개변수를 True로 지정하면 덧셈 어텐션을 수행합니다.
우리가 목표로 잡은 트랜스포머 모델은 점곱 어텐션을 사용합니다 :)
어텐션 메커니즘이 발표된 후 자연어 처리 분야에서는 LSTM, GRU 층을 사용하는 순환 신경망에 어텐션을 추가하는 형태로 발전했습니다. 하지만 순환 신경망을 사용하기에 여전히 입력되는 텍스트를 순차적으로 처리해야 했는데, 2017년, 드디어 순환 신경망에 추가하는 것이 아니라 어텐션만으로 만드는 인코더-디코더 모델이 만들어지게 되었습니다! 이 모델이 바로 트랜스포머(Transformer)입니다.

2. 셀프 어텐션
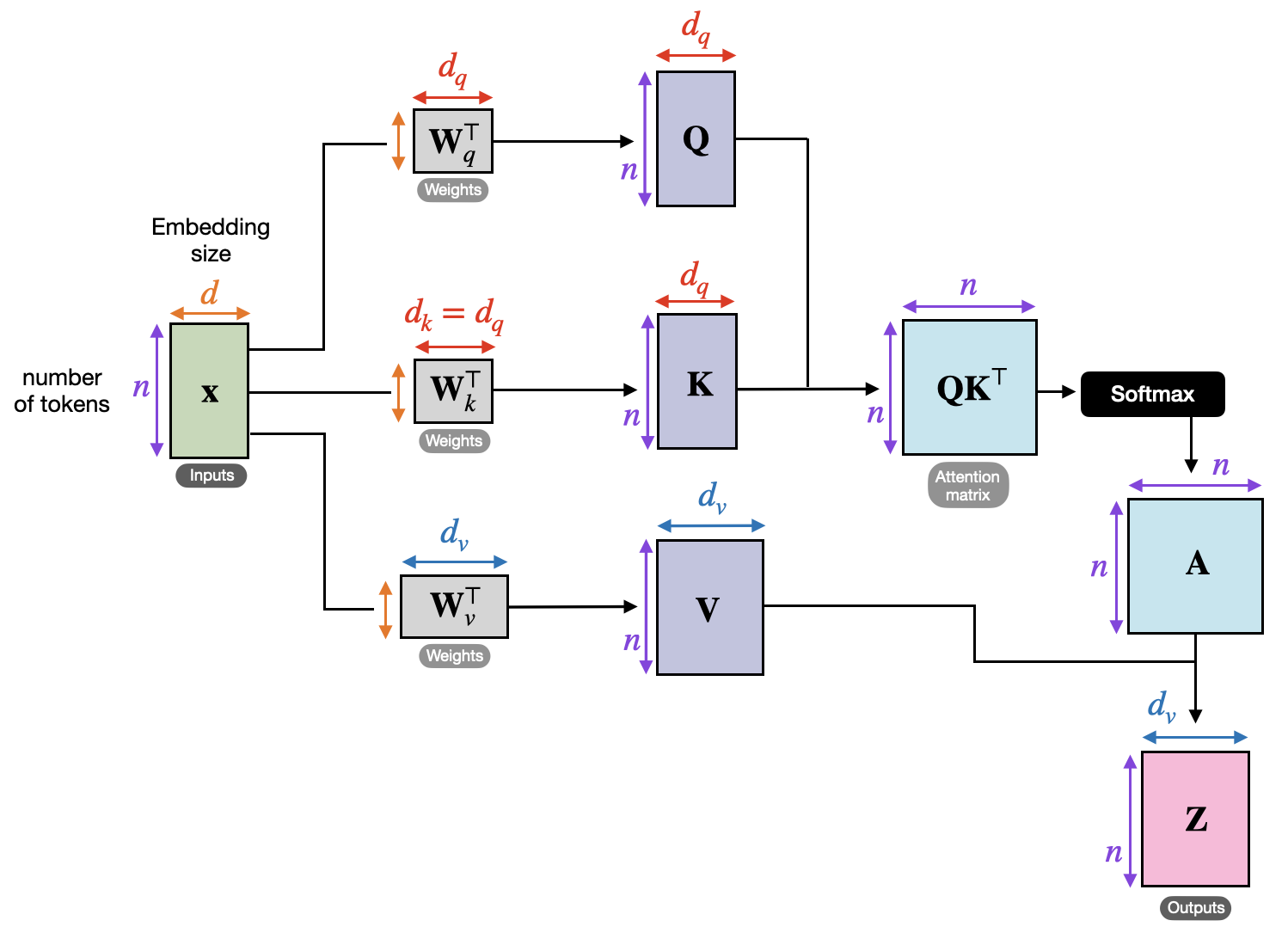
앞서 살펴봤듯이 기본 어텐션 메커니즘은 입력된 문장을 처리한 인코더의 은닉 상태와 다음 단어를 출력하기 위한 디코더의 은닉 상태를 비교해 어떤 단어가 가장 중요한지를 나타내는 어텐션 점수를 계산했습니다. 이때 트랜스포머는 인코더에서 입력 토큰을 임베딩한 벡터만으로 어텐션 점수를 계산하는데, 입력 토큰(token)이란 모델에 입력하려는 텍스트를 잘게 나눈 단위를 말하며, 일반적으로 하나의 단어는 한 개 이상의 토큰으로 나뉘게 됩니다. 또한 임베딩(embedding)은 신경망이 이러한 토큰을 처리할 수 있도록 고정 크기의 벡터로 변환한 것으로, 디코더의 은닉 상태 없이 입력 토큰만으로 어텐션 점수를 계산하기 때문에 셀프 어텐션이라고 부릅니다. 셀프 어텐션은 스케일드 점곱 어텐션이라는 방식을 사용하는데, 각각의 단어가 다른 단어들과 얼마나 관련이 있는지 계산하기 위해 다음 과정을 거칩니다.
1) 입력을 세 개의 다른 벡터로 변환
먼저 입력 토큰의 임베딩을 세 개의 서로 다른 밀집층에 통과시켜 쿼리, 키, 값 벡터를 만듭니다. 검색 엔진에 비유하면 이해하기 쉽습니다. 쿼리는 내가 입력하는 검색어, 키는 각 문서의 제목(색인), 값은 실제 문서 내용에 해당합니다. 즉, 쿼리와 키의 유사도를 계산해 어떤 값에 집중할지 결정하는 구조입니다. 일반적으로 쿼리, 키, 값의 길이는 토큰 임베딩의 길이와 동일합니다.
2) 벡터 간 관계(유사도) 및 최종 결과 계산
각각의 벡터들이 얼마나 관련이 있는지를 계산하기 위해 쿼리와 키에 대한 점곱을 수행하고, 임베딩 길이의 제곱근으로 나눠 스케일링합니다. 이를 통해 점곱 연산의 값이 너무 커지지 않도록 안정화합니다. 그리고 각 단어에 계산된 중요도를 확률처럼 확인할 수 있도록 소프트맥스 함수에 통과시켜 합이 1이 되도록 어텐션 점수를 정규화합니다. 마지막으로 계산된 어텐션 점수와 값 벡터를 곱합니다. 그러면 각 단어의 중요도를 기반으로 새로운 벡터가 만들어지게 됩니다.
이러한 셀프 어텐션을 케라스 코드로 표현하면 다음과 같습니다.
import keras
from keras import layers
def self_attention(inputs, att_dim):
# (n_batch, n_token, embed_dim) --> (n_batch, n_token, att_dim)
query = layers.Dense(att_dim)(inputs)
key = layers.Dense(att_dim)(inputs)
value = layers.Dense(att_dim)(inputs)
# score : (n_batch, n_token, n_token)
key_t = keras.ops.transpose(key, axes=(0, 2, 1))
query_key_dot = keras.ops.matmul(query, key_t) / keras.ops.sqrt(
keras.ops.cast(att_dim, dtype="float32")
)
score = keras.activations.softmax(query_key_dot)
# (n_batch, n_token, att_dim)
return keras.ops.matmul(score, value)
3개 크기의 inputs를 세 개의 Dense층에 통과시켜 쿼리, 키, 값을 만들었습니다. 따라서 각 Dense층에는 (embed_dim, att_dim) 크기의 가중치와 (att_dim,) 크기의 절편이 있습니다.
그리고 transpose() 함수를 사용하여 키를 전치하는데, 배치 차원을 제외하고 나머지 두 차원을 바꾸어야 하므로 axes=(0, 2, 1)로 지정합니다. 그리고 행렬 곱셈 함수인 matmul()을 사용해 쿼리와 키의 전치를 곱하고
att_dim의 제곱근으로 나눕니다. 마지막으로 소프트맥스 함수를 통과시킨 다음 값을 곱해서 계산한 최종 어텐션 점수를 반환합니다.
이렇게 셀프 어텐션에서 사용되는 세 개의 밀집층 가중치는 훈련을 통해 학습됩니다. 이 가중치를 통해 입력 토큰에서 어떤 단어에 주목할지 결정하는 데 도움을 주는 어텐션 점수를 계산할 수 있습니다.
3. 멀티 헤드 어텐션
트랜스포머는 하나가 아니라 여러 개의 셀프 어텐션을 사용합니다. 이를 여러 개의 어텐션 헤드(attention head)를 사용한다고 말하는데, 여러 개의 어텐션 헤드를 실행해 서로 다른 관점에서 단어의 중요도를 계산하면 문장의 의미를 더 깊게 이해할 수 있습니다. 이를 멀티 헤드 어텐션(multi-head attention)이라고 합니다.
1) 어텐션 계산
각각의 헤드가 독립적으로 셀프 어텐션을 수행하고, 각 헤드에서 계산된 출력을 하나로 연결합니다.
2) 최종 변환
하나로 연결된 멀티 헤드 어텐션의 결과를 밀집층에 통과시켜 원본 임베딩 크기로 변환합니다.
멀티 헤드 어텐션은 트랜스포머의 핵심이기 때문에 케라스에서는 MultiHeadAttention 클래스로 멀티 헤드 어텐션 기능을 제공합니다.
MultiHeadAttention 클래스에 필요한 두 개의 매개변수는 어텐션 헤드의 개수를 지정하는 num_heads와 키 벡터의 차원을 결정하는 key_dim입니다. 쿼리와 값의 크기는 키의 크기와 동일하게 설정합니다. 만약 값 벡터의 크기를 따로 지정하려면 value_dim 매개변수를 사용합니다.
# 멀티 헤드 어텐션
inputs = keras.Input(shape=(10, 20))
x = layers.MultiHeadAttention(num_heads=4, key_dim=5)(query=inputs, value=inputs)
model = keras.Model(inputs, x)
model.summary()
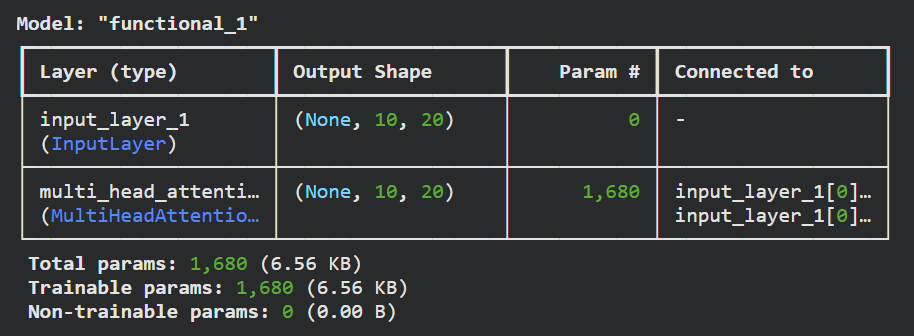
케라스 함수형 API를 사용해 간단한 모델을 만들었습니다. MultiHeadAttention 층을 호출할 때에는 query 매개변수에 쿼리, value 매개변수에 값을 전달해야 합니다. 셀프 어텐션은 한 시퀀스 안에 있는 토큰 사이의 관계를 분석하기 위해 쿼리와 값에 동일한 값을 사용합니다. 따라서 두 매개변수에 모두 inputs를 전달합니다. 또한 value 매개변수에 전달된 값을 키로 사용하지만, key 매개변수에 별도로 지정할 수도 있습니다.
1) 어텐션 계산 단계
(10, 20) 크기의 입력이 세 개의 밀집층으로 들어가 (10, 5) 크기의 쿼리, 키, 값이 됩니다. 이 밀집층에 있는 가중치 크기는 (20, 5)이고 절편의 크기는 (5,)입니다. 쿼리, 키, 값마다 이런 밀집층이 있으므로 밀집층 세 개의 총 가중치는 (20×5+5) × 3 = 315이고, 이런 어텐션 헤드가 4개이므로 315 × 4 = 1260개가 됩니다.
2) 최종 변환 단계
(10, 5) 크기의 어텐션 헤드 네 개의 출력을 연결한 (10, 20) 크기의 입력을 받아 (10, 20)의 출력을 만드는 밀집층을 거치게 됩니다. 따라서 이 밀집층의 가중치 크기는 (20, 20)이고 절편 크기는 (20,)입니다. 이 가중치를 모두 더하면 1260 + 20×20 + 20 = 1680개가 됩니다.
4. 위치 인코딩과 층 정규화
트랜스포머 인코더 모델은 어텐션 메커니즘을 통해 입력된 단어 간의 관계를 효과적으로 계산할 수 있게 되었지만, 어텐션은 순서를 고려하지 않아 단어가 등장하는 위치나 순서를 이해하기가 어렵습니다.
또한 어텐션 메커니즘의 밀집층에서 연산 과정을 반복하다 보면 계산된 값이 너무 커지거나 작아질 수 있습니다.
모델을 더 발전시키려면 문장의 순서를 이해하고 보다 안정적으로 학습하는 과정이 필요합니다. 이때 나오는 개념이 위치 인코딩과 층 정규화입니다.
1) 순서 정보 더하기 - 위치 인코딩
셀프 어텐션은 입력 토큰 사이의 중요도를 감지하는 데 뛰어난 역할을 수행하지만 한 가지 단점이 있습니다. 순환 신경망처럼 토큰이 순서대로 입력되지 않기 때문에 토큰 간의 상대적 위치와 순서를 감지하지 못한다는 것입니다.
예를 들어봅시다. “I love you because you love me”라는 문장이 있는데, 여기에서 love는 두 번 등장합니다. 만약 “나를 사랑하는 사람이 누구야?”라고 물으면 모델은 두 번째 위치에 있는 love에 주의를 기울여야 합니다. 하지만 두 위치에 있는 단어 love의 임베딩 벡터가 동일하다면 이러한 차이를 나타내기가 어렵습니다.
그래서 단어의 순서에 대한 정보를 보완하기 위해 토큰 임베딩에 추가하는 값을 위치 인코딩(PE)이라고 합니다.
원본 트랜스포머 논문에서는 삼각함수를 사용해서 토큰의 위치를 만들었는데, 삼각함수를 사용하면 벡터화된 위치를 쉽게 계산할 수 있고 삼각함수의 주기적이고 매끄러운 패턴을 이용해 위치의 연관성을 자연스럽게 나타낼 수 있습니다.
p번째 토큰의 임베딩에 d 길이의 위치 인코딩을 추가한다고 생각해봅시다. 위치 인코딩은 짝수와 홀수, 두 가지 형태로 정의되며 짝수 위치에는 sin 함수를, 홀수 위치에는 cos 함수를 사용합니다.
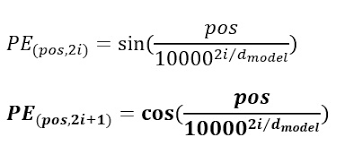
위치 인코딩은 각 토큰의 임베딩에 더해지기 때문에 일반적으로 토큰 임베딩의 길이와 동일하게 위치 인코딩의 길이(d)가 결정됩니다.
그러면 이 수식을 간단한 넘파이 함수로 구현해 위치 인코딩이 어떤 값을 가지는지 확인해보겠습니다.
# 위치 인코딩
import numpy as np
import matplotlib.pyplot as plt
d = 500
n_token = 200
pos_encoding = np.zeros((d, n_token))
for p in range(n_token):
for i in range(0, d, 2):
pos_encoding[i, p] = np.sin(p / 10000 ** (i / d))
pos_encoding[i + 1, p] = np.cos(p / 10000 ** (i / d))
plt.figure(figsize=(10, 3))
plt.imshow(pos_encoding, interpolation="quadric", aspect="auto")
plt.axis([0, n_token, 0, 200])
plt.xlabel('token position')
plt.ylabel('position encoding')
plt.colorbar()
plt.show()
먼저 토큰 개수 200, 위치 인코딩의 길이 500만큼의 빈 넘파이 배열 pos_encoding을 만듭니다.
두 개의 for 반복문을 사용해 각 토큰마다 0~d 사이의 짝수를 순회하면서 위치 인코딩을 계산하여 pos_encoding에 추가합니다.
pos_encoding 배열을 넘파이 imshow() 함수로 출력하면 -1 ~ 1 사이의 인코딩 값을 색으로 구분해볼 수 있습니다. imshow() 함수의 interpolation 매개변수는 픽셀 사이의 보간 방식을 정의하고, aspect 매개변수를 auto로 지정하면 앞서 figure() 함수에서 정의한 그래프 크기에 맞춰 자동으로 이미지를 조정합니다. 마지막으로 컬러바를 그려서 색깔에 따른 강도를 표현했습니다.
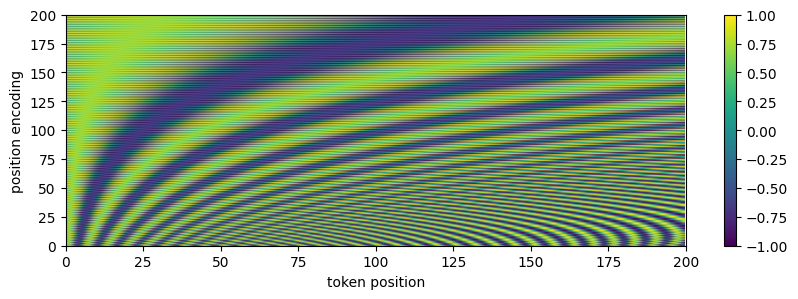
실행 결과를 살펴보면 0~200까지의 토큰이 모두 다른 위치 인코딩을 가진다는 것을 알 수 있습니다. 이러한 각각의 위치 인코딩을 토큰의 임베딩에 더하여 멀티 헤드 어텐션의 입력으로 사용하는 것입니다.
최근에는 이렇게 생성한 위치 인코딩 대신에 훈련을 통해 정수 위치에 해당하는 인코딩을 모델이 학습하는 방법을 널리 사용하고 있습니다. 이를 위치 임베딩이라고 하며, 토큰 임베딩처럼 케라스의 Embedding 클래스를 사용하면 쉽게 구현할 수 있습니다.
# 위치 임베딩
vocab_size = 10000
embed_dim = 768
max_seq_len = 512
inputs = keras.Input(shape=(None,))
token_embedding = layers.Embedding(vocab_size, embed_dim)(inputs)
token_pos = keras.ops.arange(max_seq_len)
pos_embedding = layers.Embedding(max_seq_len, embed_dim)(token_pos)
encoder_inputs = token_embedding + pos_embedding
먼저 모델의 어휘 사전 크기, 임베딩의 크기, 입력 시퀀스의 최대 길이를 설정합니다. 케라스의 layers.Embedding 클래스를 사용해 입력 토큰을 토큰 임베딩으로 바꾸고, 입력 토큰의 길이만큼 정수 인덱스를 생성합니다. 토큰 임베딩과 유사하게 layers.Embedding 클래스로 토큰 위치를 위치 임베딩으로 변환한 뒤, 토큰 임베딩과 위치 임베딩을 더하여 최종 입력을 준비합니다.
2) 훈련 안정화하기 - 층 정규화
배치 정규화는 입력 데이터가 신경망의 여러 층을 통과하면서 틀어지는 데이터 분포를 다시 배치 단위로 각 층의 출력을 정규화함으로써 훈련의 안정성과 속도를 높이는 기법입니다.
층 정규화는 배치 정규화와는 조금 다르게 배치 단위가 아니라 각 샘플의 특성을 정규화합니다. 층 정규화는 텍스트 시퀀스에 있는 토큰마다 정규화하는 것이기 때문에 시퀀스를 기반으로 하는 자연어 처리 작업에 적합한 방식이라고 볼 수 있습니다.
층 정규화는 케라스의 LayerNormalization 클래스에 구현되어 있으므로, 배치 정규화와 층 정규화를 통해 샘플 데이터가 어떻게 변화하는지 직접 구현하면서 알아보도록 하겠습니다.
data = np.arange(12, dtype="float32").reshape(2, 2, 3)
print(data)

batchnorm = layers.BatchNormalization()
print(batchnorm(data, training=True).numpy())

모든 샘플과 모든 토큰에 있는 첫 번째 특성을 정규화하였습니다. BatchNormalization 클래스의 epsilon 기본값 1e-3을 적용하면 아래와 같이 비슷한 결과를 구할 수 있습니다.
temp = np.array([0, 3, 6, 9])
(temp - np.mean(temp)) / (np.sqrt(np.var(temp) + 1e-3))

그러면 이번에는 층 정규화를 적용해보겠습니다.
layernorm = layers.LayerNormalization()
print(layernorm(data).numpy())
temp = np.array([0, 1, 2])
(temp - np.mean(temp)) / (np.sqrt(np.var(temp) + 1e-3))
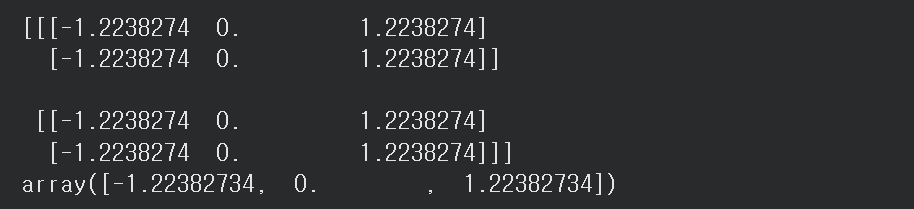
이와 같은 방식으로 층 정규화는 트랜스포머 모델에서 각 층의 출력을 정규화하여 모델을 안정적으로 훈련하는 데 중요한 역할을 합니다.
5. 트랜스포머 인코더 모델
트랜스포머 인코더는 위치 인코딩으로 문장의 순서를 기억하고, 셀프 어텐션과 멀티 헤드 어텐션으로 중요한 정보에 집중해 데이터를 처리하고, 층 정규화를 거쳐 트랜스포머가 최종 결과를 예측하는 데 중요한 역할을 하는 벡터를 생성합니다.
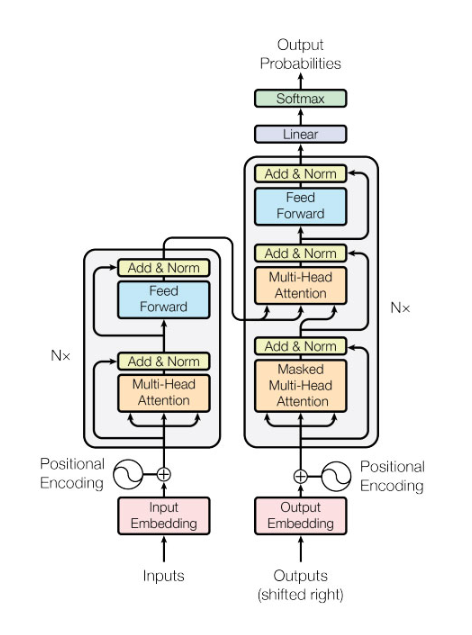
원본 트랜스포머 모델의 그림에서는 표시되어 있지 않지만, 멀티 헤드 어텐션층 다음에는 과대적합을 막기 위해 훈련 단계에서 뉴런의 일부를 무작위로 비활성화하는 드롭아웃이 놓입니다.
드롭아웃층의 출력은 어텐션의 입력과 더해져(스킵 연결), 층 정규화를 통과합니다(트랜스포머 모델에서 Add & Norm으로 표시된 부분).
그리고 위치별 피드 포워드 네트워크(position-wise feed-forward network) 또는 피드 포워드 네트워크라고 부르는 두 개의 밀집층을 지납니다.
- 첫 번째 밀집층 : 입력 벡터의 차원을 확장하는 단계로, 렐루 활성화 함수 사용
- 두 번째 밀집층 : 다시 원래의 임베딩 차원으로 축소하는 단계로, 활성화 함수 사용 X
원본 트랜스포머 모델은 첫 번째 밀집층의 유닛 개수를 임베딩의 네 배로 두고, 두 번째 밀집층의 유닛 개수는 원래 임베딩 벡터 크기로 되돌립니다. 이 두 밀집층은 시퀀스의 각 토큰에 대해 적용되기 때문에 마치 점별 합성곱과 같은 효과를 냅니다.
이어서 드롭아웃층을 지나 밀집층의 입력과 더해지는 스킵 연결을 통과한 다음, 층 정규화를 적용하여 인코더의 최종 출력을 만듭니다.
스킵 연결 직전에 통과하는 드롭아웃층은 잔차 드롭아웃, 어텐션층에서 소프트맥스 함수의 출력에도 드롭아웃을 적용하는 것은 어텐션 드롭아웃이라고도 합니다.
# 트랜스포머 인코더
# x는 토큰 임베딩 + 위치 임베딩
def transformer_encoder(x, padding_mask, dropout,
hidden_dim=768, num_heads=8,
activation='relu'):
residual = x
key_dim = hidden_dim // num_heads
# 멀티 헤드 어텐션을 통과
x = layers.MultiHeadAttention(num_heads, key_dim, dropout=dropout)(
query=x, value=x, attention_mask=padding_mask)
x = layers.Dropout(dropout)(x)
# 스킵 연결
x = x + residual
x = layers.LayerNormalization()(x)
residual = x
# 위치별 피드 포워드 네트워크
x = layers.Dense(hidden_dim * 4, activation=activation)(x)
x = layers.Dense(hidden_dim)(x)
x = layers.Dropout(dropout)(x)
# 스킵 연결
x = x + residual
x = layers.LayerNormalization()(x)
return x
transformer_encoder() 함수는 x, padding_mask, dropout, hidden_dim, num_heads, activation 매개변수를 받습니다.
배치에 있는 샘플의 시퀀스 길이가 서로 다른 경우에는 짧은 시퀀스에 0 패딩을 추가해 길이를 맞춥니다.
이때 모델이 실제 단어가 아닌 패딩 값을 참고하지 않도록 1과 0으로 이루어진 padding_mask를 사용합니다.
또한 MultiHeadAttention 클래스는 어텐션 드롭아웃을 적용하기 위해 dropout 매개변수를 제공합니다.
위 코드에서는 transformer_encoder() 함수의 dropout 값을 어텐션 드롭아웃과 잔차 드롭아웃에 함께 사용했습니다.
이렇게 트랜스포머 인코더는 입력 토큰에 위치 정보를 더한 뒤, 멀티 헤드 어텐션과 피드 포워드 네트워크, 스킵 연결, 층 정규화를 거치며 문장의 의미를 담은 벡터를 만들어냅니다. 실제 모델에서는 이러한 인코더 블록을 여러 개 반복해서 더 깊은 표현을 학습할 수 있습니다.
원본 트랜스포머는 인코더와 디코더를 함께 사용하는 구조이지만, 작업 목적에 따라 인코더만 사용하는 모델도 있고 디코더만 사용하는 모델도 있습니다. 이번 글에서는 그중 인코더 구조를 중심으로 살펴보았습니다.
다음 글에서는 트랜스포머 디코더 모델에 대해 알아보겠습니다. 감사합니다.